 Backup
Backup
A proposal for a new open source backup solution
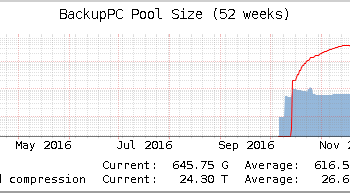
I started my first business with offering a backup solution. This was back in year 2000, using Bacula and rsync. Ever since, I have been involved in providing backup solutions, and developing extensions to them. Our current business offers both BackupPC and UrBackup. Furthermore, our ownCloud and Nextcloud services have some very nifty aspects that are applicable to backup contexts.
With the increasing focus on cloud solutions and scalability, I find there is a gap in the open source backup offerings. In this post I explore the features needed and propose a new backup solution or a goal that current solutions can evolve into.
Drawing ideas from the best
As evidenced by our offerings, I consider BackupPC, UrBackup and ownCloud / Nextcloud the best fit solutions out there at the moment. However, they have very different architectures and use cases. The respective key features I desire of a backup solution are listed below.
BackupPC version 4
- Cross-client pre-transfer deduplication
- Hash based storage
- Storage integrity checks
- Works without client app
- Smart configuration management
- Work splits into several processes per client
- Storage compression
- rsync based file transfers with compression
UrBackup
- Image backup with differential transfer
- Real time web UI with progress information
- Client package generation
- Client app that reaches behind firewalls
- Intelligent file system back-ends
- rsync based file transfers with compression
- Users, roles and groups
- Asynchronous storage handling
Nextcloud / ownCloud
- Object storage support
- Proper database
- Scale-out capability
- WebDAV
- Continuous connectivity check to storage
- Maintenance mode
- Users, roles and groups
Proposal for a new open source backup solution
Putting the above features together, I propose the features of the new backup solution. As I mentioned, this could be a new project or an evolution of any of the existing applications. Naturally, it may take place over several major versions, with only one key aspect – such as migrating to a database – on the roadmap each time. Regardless, it would likely break backwards compatibility with any of the existing solutions.
Key features
- Scale out capable, i.e. can run multiple parallel instances
- High availability capable, i.e. all components can have redundancy
- Clean webapp + database + hash based storage model
- Stateless application instances (discardable incomplete backups or redis + shared cache)
- Modular to allow easy development adding back-ends, clients and so on
- Stable APIs to allow easy development of integration and apps
- Cross-client pre-transfer deduplication
- Differential data transfer with compression (obviously rsync, but even better compression may pay off)
- Storage compression
- Storage integrity management
- File and image backups
- Web UI and CLI
- Smart configuration management
- Thread scalable
- Client app package generation
- Client app allowing backing up mobile clients behind firewalls
- User authentication and self service based on authorization for specific roles in specific groups
- End-user web accounts
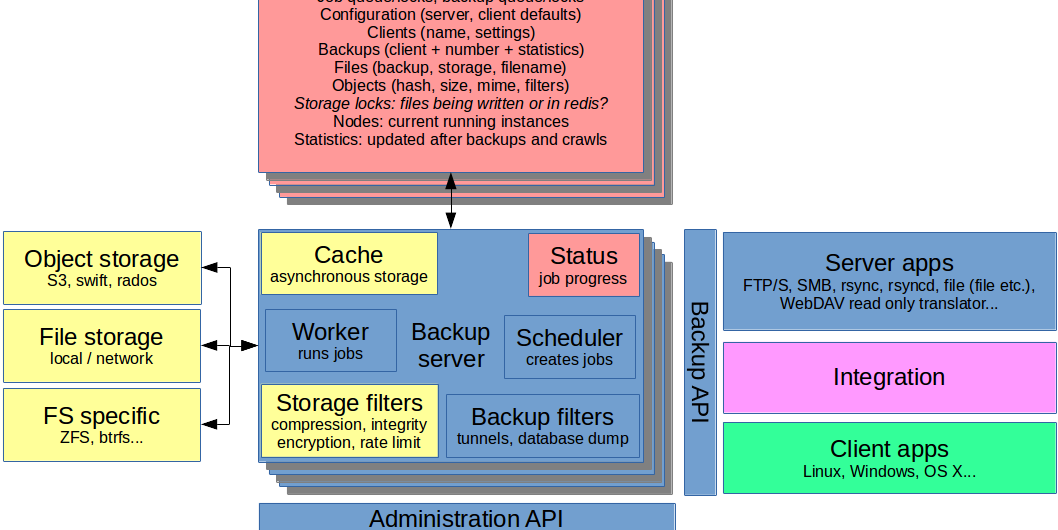
Architecture overview
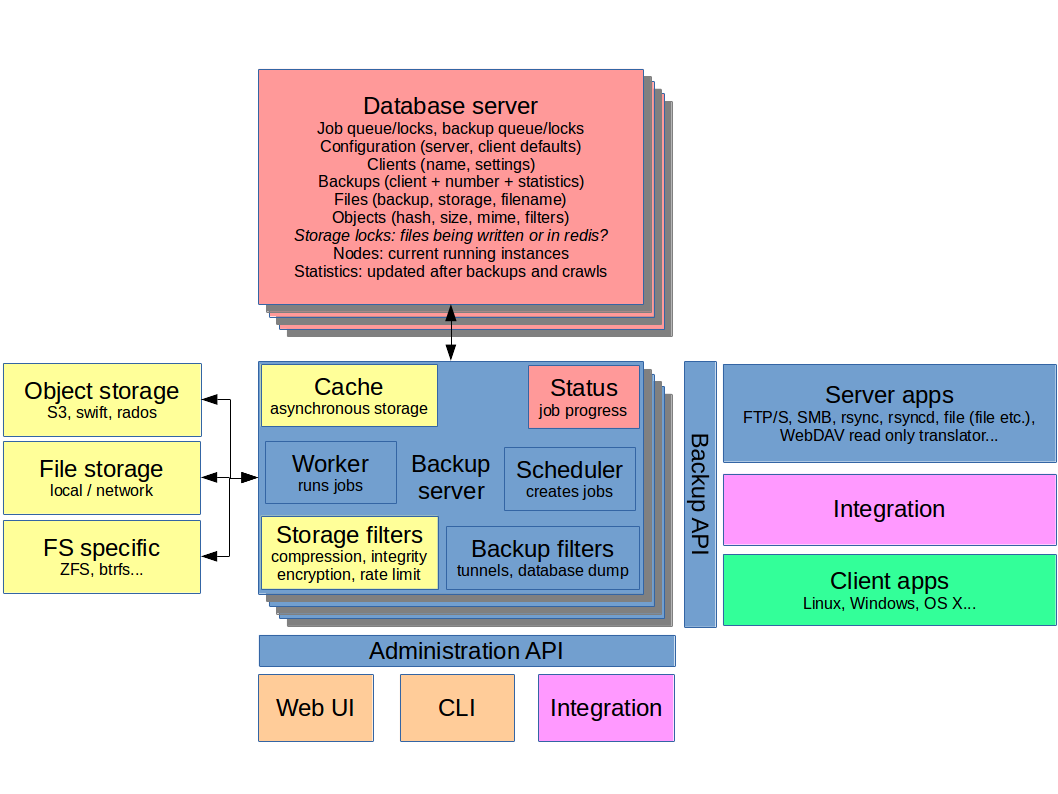
Backup server
To the extent possible, we should follow proven webapp design principles. However, the backup server may indeed benefit from running native code rather than implementing everything in PHP or similar. In case the solution evolves from existing ones, there may be a natural choice for the design of this part already – if it can be scaled out.
Furthermore, the backup server core itself is kept as simple as possible. This is achieved by moving backup methods and user interfaces outside the core. The concept of filters adds simple rules that likely only consist of a few lines of code. Filters can be applied to any job, so they are best served internally.
Storage abstraction can also help minimize the complexity of the backup server. However, going as far as moving those behind an API does perhaps not make sense for many reasons.
The server manages all configuration aspects in the database, except for the database connection configuration itself.
The server can also contain a temporary storage to allow for slower storage back-ends to be used without slowing down the backup itself. This decoupling is important especially for object storage.
The volatile information kept on each instance is accessed and collated by the CLI and the web UI. A good example, while overkill for these purposes, is netdata. It may also be simpler to combine the data in the administration engine before the API.
Backup filters add functionality to backup jobs. Examples include starting SSH tunnels or SSL stunnels, as well as running pre/post commands such as MySQL dumps.
Key components
The backup engine listens on the Backup API. In addition to working with the database and storage, it carries volatile information about the backups in RAM such as progress and data metrics. The backup engine manges file and block checksumming, deduplication and of course logging.
The administration engine listens on the Administration API. In addition to working with the database, it carries volatile information about the instance in RAM, such as load and running jobs.
The scheduler creates jobs and backups into the queue.
The workers run jobs and initiate backups in the queue. Running a job can be a crawl to check the integrity of the storage or sending an email. Initiating a backup will inform the client to start the process or to run a server app with given parameters.
Storage
Storage builds on two pools, one each for file (whole objects) and disk images (full images and differentials). These are accessed through back-ends that take care of talking to the storage. The storage filters modify the traffic between the application server and the storage when enabled.
The file storage structure is hash based. This allows even for migrating between storage types without worry for long file names etc. The files are stored in hierarchical subdirectories for for 8 first bits each and two levels deep. An example of this is ‘6e/fa/6efa018054c8e1748b97e7313b7651ca’. This allows for fast indexing on object storage. Beyond that the pool only contains an identification file with the structure version and a unique ID that is matched with the database. Reading that file also works as a connectivity check.
The disk image backups are similarly hashed or numbered. Importantly, object storage has limitations especially in regards to random access and sometimes read speeds. Thus, one thing to overcome in this aspect is how to optimize differential backups of large files such as disk images, when using object storage. Since image storage forms a separate storage pool, one approach is to allow it to use a separate storage back-end that allows block access.
Back-ends
There are three main categories of back-ends. The simplest one is pure file back-end works on top of almost anything, even object storage mounts for testing purposes. The second category is object storage back-ends such as S3, swift and rados. The third category includes any enhanced file back-end that is able to make intelligent use of the underlying filesystem. Key things to look for are compression, data integrity mechanisms and snapshotting features of the filesystem. While otherwise attractive, this third category does not scale out well. Likewise, ensuring high availability is more challenging, as it requires block-level network replication or cluster file systems, negating many benefits of pure local storage.
Eventual consistency assurance filter
None of the existing solutions support ensuring that data was stored when using eventual consistency paradigm storage, especially using object storage solutions. Most PUT commands’ failures can be detected right away such as those received as HTTP response codes, others may not. This is due to the fact that the response can be received before the storage back-end replicates the data. Essentially, eventual consistency assurance includes simply reading the file again after storing it, possibly after a delay. If something fails, it retries GET and PUT a number of times. This combines especially well with asynchronous storage cache.
Rate limiting filter
Limiting storage rates may sound counterproductive but is a definite case for object storage. In object storage contexts rate limiting typically is defined in terms of commands/time period, such as 100 PUT requests per starting 5 seconds. Since file sizes vary, this results in a varying bandwidth. The setting could be manged with reactive intelligent code that understands response headers, or proactive limits that are set internally.
Compression management filter
Compression, or rather managing compression, can bring benefits especially where storage space and storage I/O is more expensive or limiting than CPU cycles. However, compression may be more efficient outside the backup solution. This is the case with some file systems, for example ZFS provides excellent compression mechanisms. With other back-ends that lack file system level compression, such as file or object storage, compression can be provided internally. Furthermore, intelligent mime management can be used to preempting compression rather than the typical trial-and-error model.
Data integrity management filter
A scheduled data integrity crawler can detect any bit rot before a restore is needed. As with compression, this may be most efficient outside of the backup solution. Again using the ZFS as the example, it provides excellent tools for this purpose. There is a scheduled scrub, and individual files checks can also be requested. Beyond that, ZFS can fix bit rot when running on redundant storage. Tapping into these features or being aware of them avoids unnecessary redundant tasks and enables smarter error correction. Where such tools are not available, checks can be provided internally by the filter itself.
Encryption filter
Encryption adds another layer of protection for the data stored. It could be either client account based end-to-end encryption or more simply deployment-wide. Both modalities also alleviate some worries in scenarios where the storage location is an untrusted or remote object storage service.
Database
A rough schema is presented in the architecture overview above. Compared to metadata contained in directories and attribute files, a database enables scale-out at the cost of some complexity. At the same time, the potential speedup is huge. The greatest concern is to keep the database small. Only the files and objects tables will grow enormously, so the focus needs to be on those.
Obviously, the choice of hashing algorithm has to be considered for both speed and reliability. With Google having demonstrated real-world collisions with SHA-1, the choice lies between having a light algorithm and handling collisions in a sensible manner, or using a stronger algorithm. At least BackupPC has an excellent solution for this already. In the end, including collision handling may be more future-proof than simply relying on a stronger algorithm.
One further aspect to be explored is how file locks should be handled. Nextcloud / ownCloud for example, manages these in the database, but I am worried about the performance impact it may have, as well as the writes it causes. In-memory solutions may be a viable alternative for file locks. However, in order to support scaling out, that requires distributed variants such as Redis, which in turn increases complexity compared to the database approach.
Backup API
The Backup API is where the data to be backed up or restored is moved. Optimally, the Backup API is an ordinary REST API. This allows easy implementation with SSL for remote integrations, as well as fast local socket access. Highly optimized backup methods such as rsync or client applications can benefit from having a specialized interface, though. An example is the way UrBackup has a dedicated port for client connections. For this, I would suggest we explore further how much abstraction these methods can handle.
One very big concern I have here is how well this setup performs. On the one hand, BackupPC version 4 brings its own customized rsync tool written in C. If I understand correctly, it crosses all the way from the client connection to the file storage in order to improve performance. On the other hand, Nextcloud / ownCloud manages huge amounts of files very efficiently despite going through many layers of PHP code.
Furthermore, the question remains if is it at all possible to interface natively with rsync on the server side, short creating a virtual mount with FUSE. If not, it would require librsync or a custom implementation, such as the one found in BackupPC version 3.
Client apps
Client apps have the advantage of being able to offload the server even more than rsync. This can be done by sending file lists and checksums for the client to examine, as well as perform encryption and compression. In addition, it enables more functions to be performed, such as image backups and OS-specific tricks like volume shadow copy on Windows.
Server apps
The server apps are suitable for server-initiated, client-less backups. Thus, the advantage of server apps is that they can be used without modifications to the client, save for providing the necessary authentication. This category contains all standard protocols such as rsync, rsyncd, FTP/S, and SMB. Also more crude cases can be covered such as streamable or randomly accessible archives (tar with compression, 7z, zip and so on). Another interesting idea is a read only WebDAV translator. Even a database dumper can be done, although especially remote servers benefit from dumping locally first to finish the transaction as quickly as possible.
Administration API
The Administration API follows the same basic REST, HTTP, SSL, local socket model of the Backup API. It can be simply a different endpoint. The information transferred through this API is for configuration and monitoring as well as manual control.
Command line interface (CLI)
As with many modern tools, a single command line utility can talk to the API and make everything available for scripting and interacting with the backups. It could possibly even talk to the Backup API for backups and restores from stdin/stdout. One example of a successful CLI in my opinion is the LXD CLI, ‘lxc’.
Web UI
A nice web UI is a key selling point today. It is less intimidating for first time users, and enables data owners to access their backups independently. The same information is available through the web UI as with the CLI.