 Backup
Backup
BackupPC version 4 in development allows for better scaling
As one of our key offerings, BackupPC is both a service that we sell and a tool that we use internally. To give something back to the open source project, I have participated in the BackupPC community for a long time.
Lately, I contributed simple instructions and a script for Installing BackupPC 4 from git on Ubuntu Xenial 16.04 LTS in order to enable more people to get involved in testing. In this post, I take a step further to look into how well BackupPC version 4 scales in the cloud.
Pushing BackupPC to perform even better
Recent discussions on the BackupPC mailing lists inspired this post. My perspective in these discussions is mostly focused on where the project is at in relation to scaling in the cloud. Everything discussed here reflects on version 4 of BackupPC. It is in active development, and this may still change before the actual release. But already now, there are many improvements that allow for better scaling. I will cover these below.
First of all, all of the features that benefit smaller installations of course apply to larger installations as well. For example, deduplication now happens before transfer and across the whole instance. This means that when any host has backed up a particular file, no hosts will need to transfer that to the server anymore. It is simply referenced from the storage pool. The same applies to benefits from the new “filled” backup mode, which allows for unlimited reverse incrementals, which in turn decreases the load on the server.
What about solutions specific to the cloud?
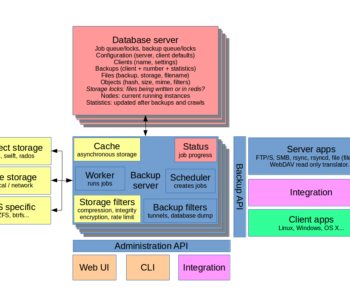
In cloud contexts, there are several attractive tools that could benefit BackupPC. As is typical, the key components are computing, database and storage. The database case for BackupPC is slightly different from typical solutions, though.
Database and computing
Running BackupPC as a symmetric/same-config scale-out solution is not possible at the moment. This is due to how it handles metadata such as file references. The information is currently kept as plain folders and files, as well as reference index files. All of these require exclusive access. In other words, there is no traditional database that can be shared among instances. Splitting up the work between instances is perfectly doable, though, but sacrifices deduplication between the instances. Obviously, scaling up and running more backups in parallel is also an option. The web front-end is never likely going to need more power, but for high availability purposes this component, too, would need to scale.
Storage
Since BackupPC is obviously very storage oriented, this is where the cloud potential lies.
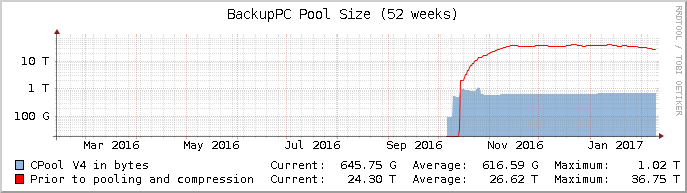
Object storage is not yet feasible in v4. This is due to some database-like files being kept in the parts that would go into object storage (cpool). Also, in the current development builds, there are several fairly heavy operations on the cpool that would slow it all down too much. Some of these operations may be avoidable in future builds. However, the new cpool structure itself is quite a good fit for object storage: it is hash based and divided into neat hierarchical subfolders that allow fast indexing. And most critically, BackupPC no longer relies on hard links.
If we are talking PB’s of data, node-based local storage is likely not feasible. If the files are mostly large, then network based storage is a good option. While object storage is not yet on the table, my experiences with ceph remote block devices in this kind of setting are positive. This also fits the scale-up model for now, since block devices typically are limited to one instance at a time. Beware however, that if the files are mostly small, there may be hit by random access latency with any network-based solution.
If the data is a mix of large and small, an option to consider is splitting up the data on two instances according to file size. Especially if the small files can fit on local storage where small random I/O is orders of magnitude faster, we can reap the benefits of both models by splitting it up.
ZFS is a good fit for BackupPC
In order to scale the filesystem itself, I would opt for a copy-on-write (CoW for short) filesystem, since these fit the case of storing static files well. Most CoW filesystems also come with data integrity verification out of the box.
ZFS is a CoW filesystem, and key benefits of it in this context are:
- Data integrity verification
- Automatic bit rot fixing when running ZFS built-in RAID
- Snapshot send/receive for remote replication faster than rsync
- Transparent compression
- Dynamic, on-line resizing
In other words, with ZFS, it is possible to handle both compression and data integrity checking outside of BackupPC. This speeds things up a lot and making it use more threads.
I have not tried ZFS on ceph yet, though. Balancing the redundancy optimally will be an issue in this scenario. Taking advantage of both ceph and ZFS easily costs 4 times (twice for each, or ~1.3 times for ZFS and three times for ceph) the space of the data to be stored plus plenty of RAM. (Note that googling ‘ZFS on ceph’ gives a lot of issues about ceph on ZFS OSD’s, which is irrelevant here.)
Tip: run the pc folder off SSD
Finally, here’s a tip for anyone deploying the latest BackupPC version 4. Split the storage up on SSD for the pc folder and something more cost efficient for cpool such as SMR drives. This was not possible before version 4, so existing installations cannot make use of this.
The pc folder in version 4 essentially only contains the directory structures and references of files that they should contain, so it stays very small. However, it is often read from and speeds things up remarkably when it is served fast. Much more so than speeding up the cpool.